Creating a migration wave
Forge migrates Teradata and Oracle workloads to BigQuery (or Cloudera). The unit of work is a wave: a named set of artifacts (tables, views, procedures, UDFs, macros) you migrate together. Waves are how you sequence a large migration into reviewable, deployable chunks.
This page walks you through setting up a project and creating the first wave inside it.
Goal
You finish this page with a Forge project connected to a source database, a wave created in the project, and the artifacts you want to migrate added to it.
Prerequisites
- A source connection (Teradata or Oracle) configured by your admin.
- A target BigQuery dataset (or Cloudera target, depending on your migration's destination).
- A workspace to anchor the project to — Forge projects are workspace-scoped, like notebooks and dashboards.
- The forge access permission in your role.
Steps
1. Open Forge
Hover the menu (≡) and click Forge.
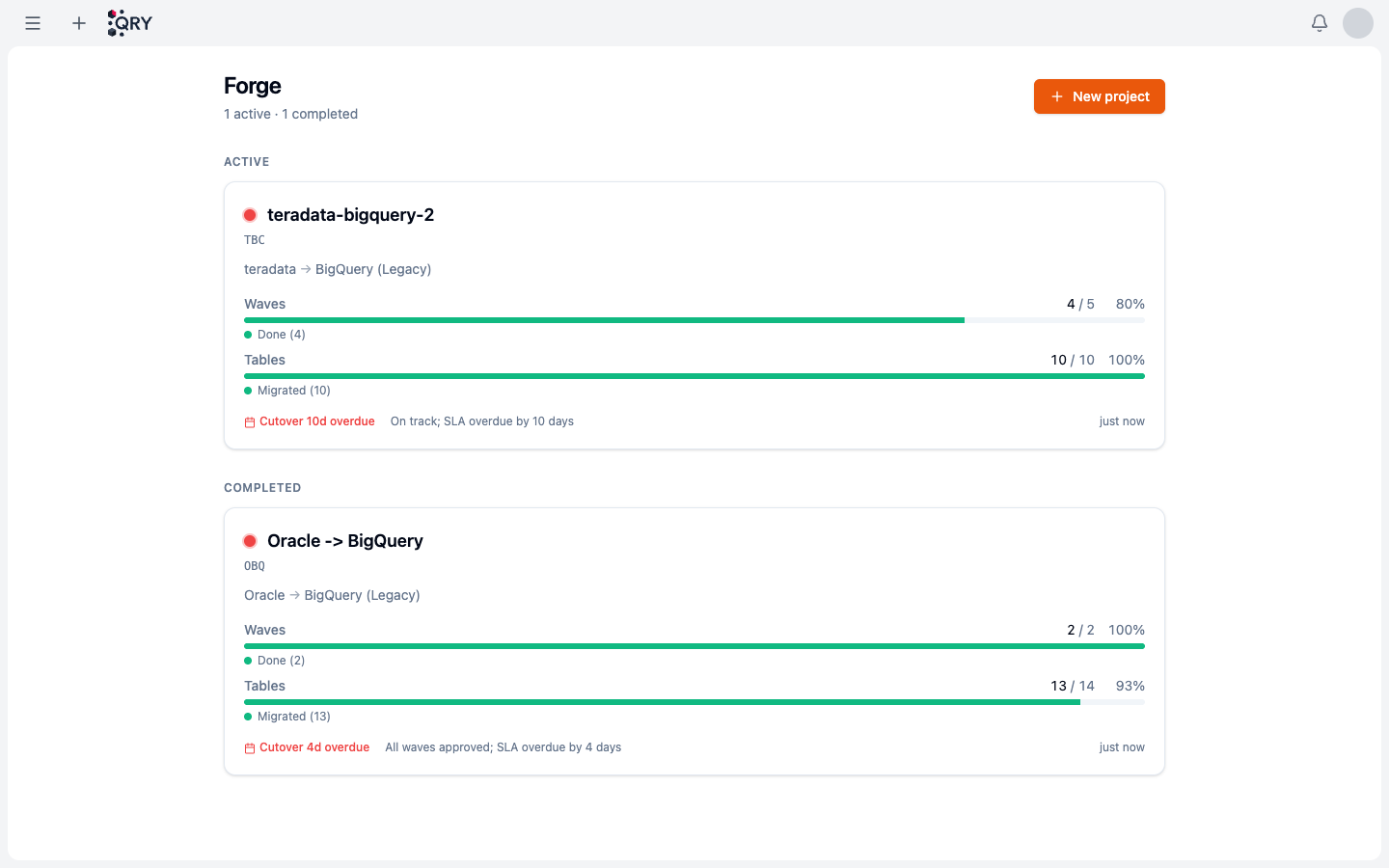
The landing has two sections — Active projects (in-flight migrations) and Completed ones. Each card shows the source → target combo, two progress bars (waves done out of total, tables migrated out of total), and any Cutover SLA overdue flag in red.
If your tenant is starting fresh the list is empty, and the page invites you to create your first project.
2. Create a project (or open an existing one)
Click New project. The wizard has four steps along the top: Identity → Connect → Scope → Plan.
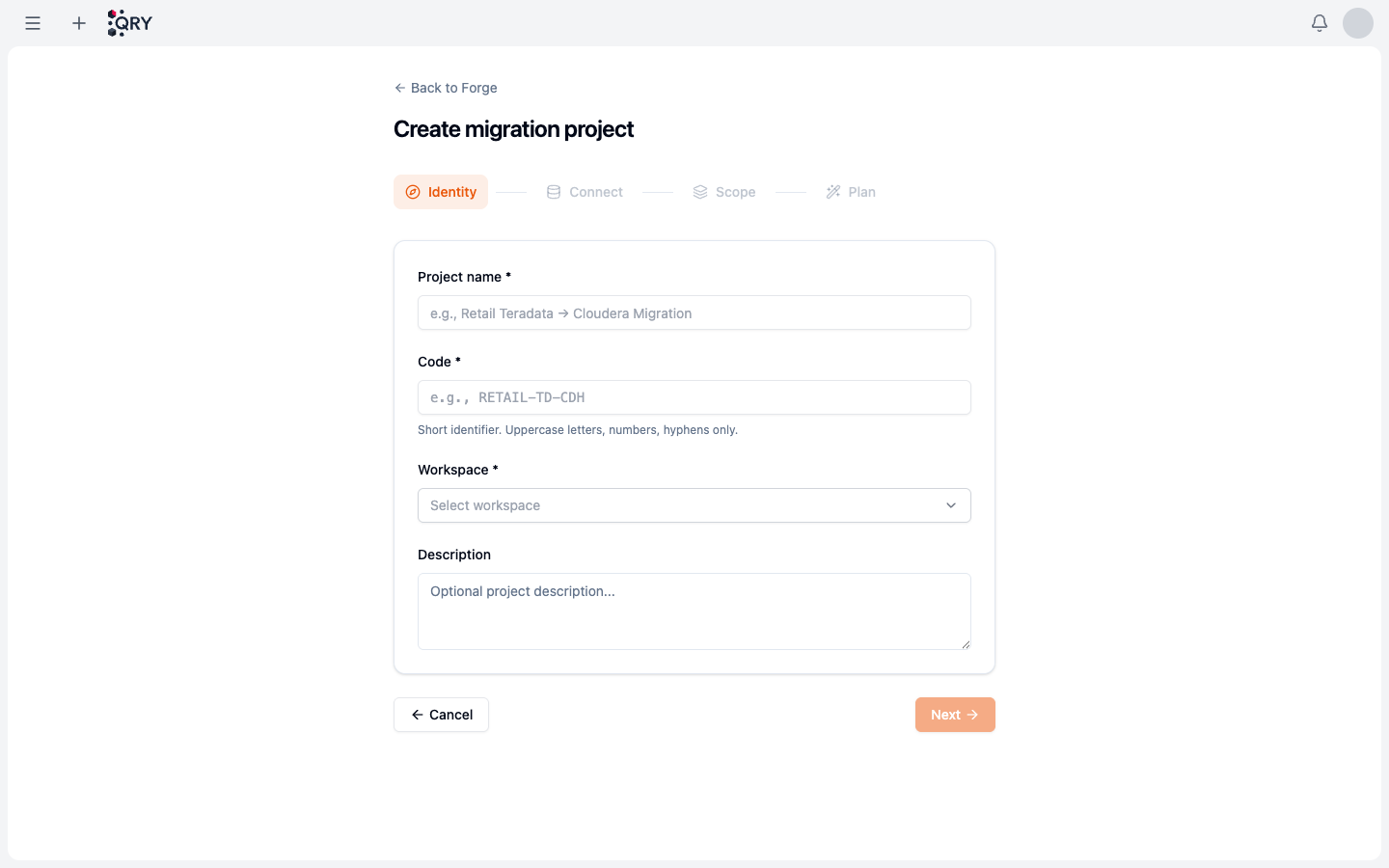
- Identity — Project name (e.g. Retail Teradata → BigQuery Migration), a short Code (uppercase letters, numbers, hyphens only, e.g.
RETAIL-TD-BQ) that tags the project across logs and metrics, the Workspace the project belongs to, and an optional description. - Connect — pick the source connection (Teradata or Oracle) and the target (BigQuery or Cloudera), both from connections your admin configured.
- Scope — choose which catalogs / databases / schemas of the source to ingest into the project's artifact catalog. Tighter scope = faster metadata ingestion + cleaner project.
- Plan — review and confirm. Translation is enabled by default; admin-controllable via
runtime_config.forge_translation.enabled. With it disabled, Forge can still copy tables but won't auto-translate views / procs / UDFs / macros.
Click Create. The project opens with empty waves and an artifact catalog populated from the source database's metadata for the scope you selected.
3. Create a wave
Inside the project, open the Waves tab and click New Wave. A wave needs:
- Name — descriptive, scoped to the project.
- Owner — who's accountable for it.
- Description (optional) — what the wave covers.
The wave is created in Draft state. You can add and remove artifacts freely while it's draft.
4. Add artifacts to the wave
Browse the project's artifact catalog (under the Artifacts tab or via the catalog sidebar) and add what belongs in this wave. Two categories of artifact:
-
Tables — the actual data. These migrate either by direct copy or via Lakeflow:
- Direct copy — default for tables ≤10 GB and ≤10 M rows.
- Lakeflow delegation — automatic for tables >10 GB or >10 M rows. Forge generates a Lakeflow pipeline and runs the transfer through the external Spark cluster.
You don't pick which path — Forge does it from the metadata.
-
Translatable artifacts — views, stored procedures, UDFs, macros. These get auto-translated to BigQuery dialect via LLM with bounded self-heal: if a translation fails to deploy, Forge re-prompts with the deploy error and retries up to N times before flagging the artifact for manual review.
When you add an artifact, Forge runs an initial impact analysis (dependencies, estimated row count for tables, character count for translatable artifacts) and shows it in the wave's row.
5. Trigger translation
For waves with translatable artifacts, click Translate Wave. Forge queues each artifact for LLM translation. Progress shows per-artifact in the wave's table:
- Pending — queued.
- Translating — LLM is working.
- Translated — output ready, awaiting review.
- Failed — translation didn't produce valid SQL after retries.
For tables, no translation is needed — they go straight to the validation phase.
Result
A wave in your project, populated with the artifacts you want to migrate, with translations either queued or completed and ready for review.
Common issues
The wave's Translate button is disabled.
The translation feature flag is off (runtime_config.forge_translation.enabled = false) at tenant level. Ask an admin. The emergency global kill switch (FORGE_GLOBAL_KILL_SWITCH env) also disables it tenant-wide.
An artifact's status is "Translation Failed". The LLM couldn't produce SQL that survives the self-heal loop. Open the artifact for manual review — the Reviewing translations page covers the workflow.
A table I added is missing from the wave. Look at the wave's metrics: tables >10 GB / >10 M rows route to Lakeflow and may show under a Pipelines sub-tab instead of the main wave row. Same wave, different execution path.
The artifact catalog is empty. Source-database metadata hasn't been ingested. Trigger a refresh from the project's settings, or ask an admin to check the source connection.
I added the wrong artifact and want to remove it. While the wave is in Draft, click the artifact's row → Remove from wave. After the wave is approved, removal requires creating a follow-up wave.
See also
- Reviewing translations — what to do once translations land.
- Approving and deploying — run validations, unlock the gate, deploy.
- Forge reference — full feature reference, including metric names (
qry_forge_*) and the alert group (qry.forge).